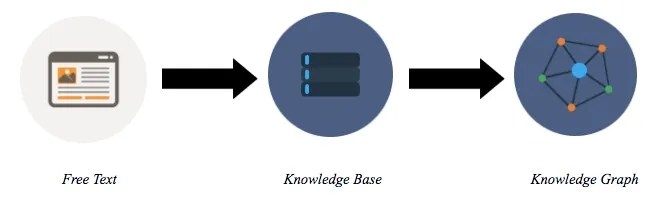
互联网的出现允许大量内容创作者访问以生成信息。正因为如此,现在网络上出现了大量的数据。为了提供有用的见解,我们需要一种有效的方式来表示所有这些数据。一种这样有效的知识表示方法是通过知识图谱。简而言之,知识图谱是一个由相互连接的数据组成的大型网络。知识图谱是根据知识库构建的。知识库从网页、数据库、音频和视频内容上的免费文本中收集信息。知识图谱构建过程的基本流程如图所示。
在这里,向大家推荐一下中培IT学院机器学习、深度学习、计算机图像处理及知识图谱应用与核心技术实战课程,课程详细讲解了包括但不限于知识图谱构建的相关知识。
现在,让我们详细了解一下在这个管道中发生的过程。
在管道的第一阶段,我们从自由文本中识别事实。最初,我们在互联网上搜索,通过从自由文本中识别实体和实体所涉及的关系来过滤有用的信息。这个识别过程使用自然语言处理技术进行,如命名实体解析、引理化和词干。因此,在第一步中从自由文本中提取的数据可能类似于以下语句的形式。
“卢浮宫位于巴黎”
进入管道的第二阶段,在知识库中以三元组的形式对语句进行概括;这些三元组将被分类在不同的本体下,使用本体提取过程,该过程也可以利用自然语言处理技术的能力。三元组由主语、谓语及其宾语组成。主语和宾语是谓词定义的关系中所涉及的实体。因此,对于前面从自由文本中确定的陈述,我们将其分解为以下知识库的三元组形式。
主题:卢浮宫
谓词:位于
对象:巴黎
因此,在一个知识库中,我们将以islocated(巴黎卢浮宫)的形式存在上述关系。这是知识库中的单个三元组。在实践中,知识库包括数百万这样的三元组,我们也将其称为事实。这些事实在知识库中被归为本体论。本体论是事实的特定领域的一个识别类别。因此,本体论解释了该类别中存在的实体类型。例如,如果本体是“机场”,那么,属于这一类别的一些实体可能包括“addison机场”、“charles de gaulle机场”和“mandelieu机场”,等等。
知识库可以是特定领域的,也可以是通用的。医学知识库和学术研究论文知识库是一些特定领域的知识库。然而,通用知识库并不将其知识限制在特定领域。它们涵盖了更广泛的世俗事实和多个领域。
在我们进入管道的最后阶段,即知识图谱之前,请参阅下表,了解从原始论文中理解的各种知识库的一些特征。该表列出了过去几十年中最重要的知识库。
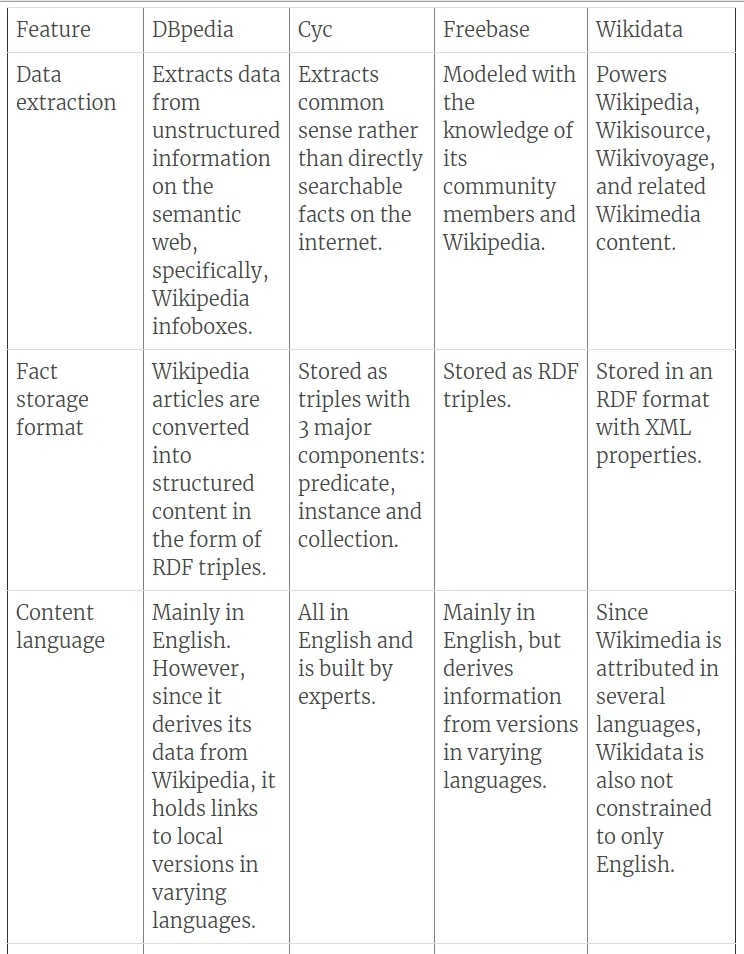
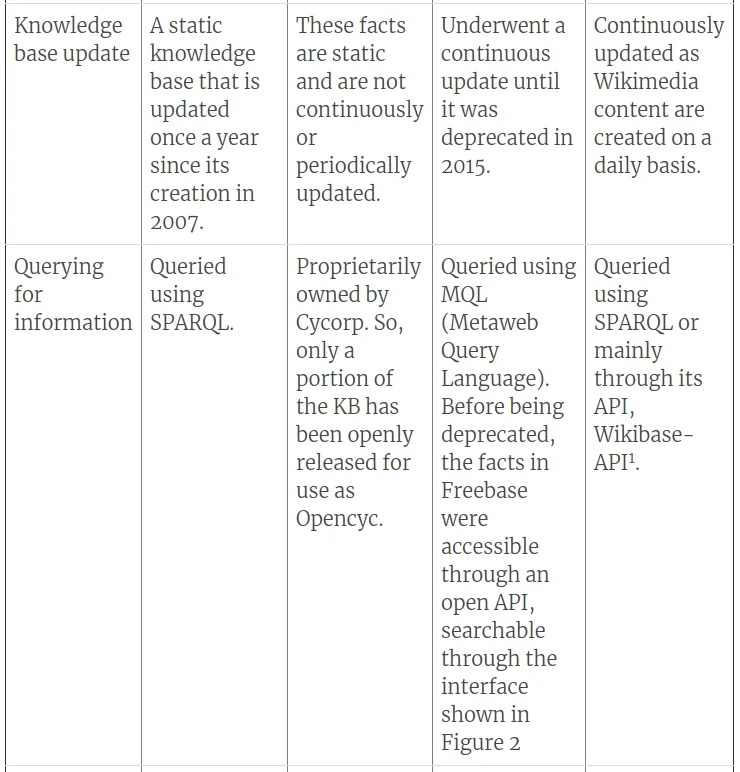
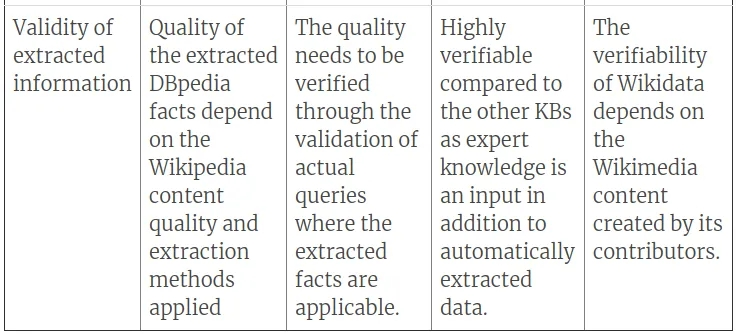
关于知识库,让我们进一步解释NELL知识库,因为我们将考虑NELL处理事实的方式,作为我们稍后将讨论的管道的知识图谱构建阶段的样本。
NELL知识库
Never Ending Language Learner(NELL)是卡内基梅隆大学于2010年启动的一个项目。它的建模是为了弥补学习系统和实际人类学习之间的差异。因此,它基于这样一个概念,即对事实的不断学习塑造了专业知识。自2010年以来,NELL一直在不断学习事实。这个知识库主要执行两项任务。
1.信息提取:搜索语义网以发现新的事实,积累这些事实并不断扩展其知识库。
2.增强学习过程:基于以前提取信息的经验,NELL试图通过返回前一天从中了解事实的页面并搜索新的事实来提高学习能力。
NELL的事实基于本体论分类:实体或关系。基于实体的本体分类由可能发生在该领域中的实例的子域组成,而基于关系的本体分类包括基于连接实体实例的关系的事实的子域。NELL中的事实是三元组(主宾谓语)的形式。例如
示例:“自由女神像位于纽约”
作为三元组,上述事实可以表示为locatedIn(statueOfLiberty,New York),其中,
主题:自由女神
谓词:locatedIn
对象:纽约
NELL的事实是使用文本上下文模式、正交分类器、URL指定的ML模式、学习嵌入、图像分类器和本体扩展程序提取的。目前,NELL受到限制,因为它无法修改其定义的学习过程。如果学习过程可以在先前学习经验的基础上动态增强,那么NELL可以提高其事实的质量和积累事实的性能。
现在,让我们进入管道的最后阶段,看看知识库中的三元组是如何转换为知识图谱的。
知识图谱
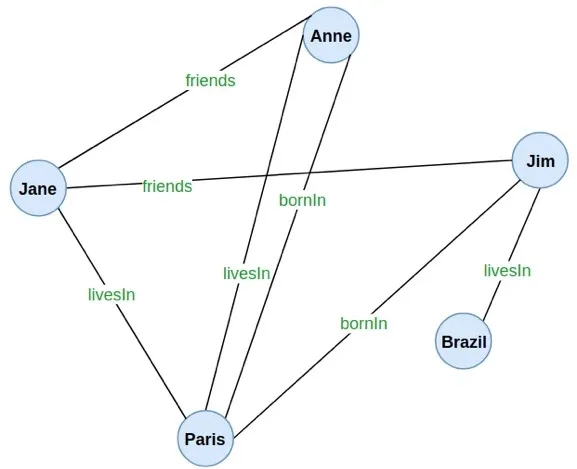
知识图谱是一个由相互连接的实体组成的大型网络。这些连接是基于知识库中的三元组创建的。知识图谱的主要目的是识别实体之间缺失的链接。为了进一步解释这一点,让我们考虑一下我们从知识库中收集的以下样本关系。
朋友(安妮,简)
朋友(简、吉姆)
LivesIn(安妮,巴黎)
LivesIn(Jim,巴西)
LivesIn(Jane,巴西)
博恩(安妮,巴黎)
BornIn(Jim,Paris)
如果我们试图仅基于上述关系来构建一个基本知识图谱,我们将能够可视化下图。
另一方面,存在一些未从知识库中明确检索到的未知关系,例如,
安妮和吉姆是朋友吗?
简的出生地是哪里?
这意味着这种关系可以被视为缺失的环节。
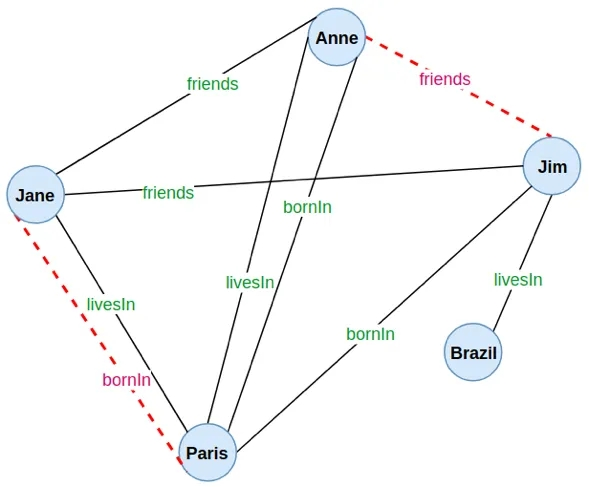
这些缺失的环节是使用统计关系学习(SRL)框架推断出来的。这些SRL框架计算推断/预测链接的关系置信度。以前的工作试图以不同的方式发现新的/缺失的信息,并计算推断这些信息的置信度。下文将简要讨论这些问题。
在管道的第一阶段,我们从自由文本中提取事实,我们也经常以错误的事实告终。为了从这些事实中识别出一个稳定的知识图谱,Cohen等人提出了一种联合评估提取事实的方法。这种方法的问题在于,它只考虑了提取的事实中可能出现的一组微不足道的错误。
作为管道的第二阶段,我们从提取的事实中找到三元组,这些三元组将构成知识库。在此过程中,在最后阶段,我们需要通过从知识库三元组中推断缺失的链接来发现新的事实。为此,继Cohen之后,Jiang等人采用马尔可夫逻辑网络来发现提取的事实之间的关系。他们定义了以一阶逻辑规则的形式指定的本体论约束。这些约束将管理可以推断的可能关系。然而,在马尔可夫逻辑网络中,我们称之为“谓词”的逻辑关系只能为其变量取布尔值。这在推断对事实的置信度方面是不利的。
这导致了概率软逻辑(PSL)的定义,它使用了Jiang等人和马尔可夫逻辑网络的概念,并定义了一个复杂的统计关系框架,该框架对所有事实进行联合推理,以在先前事实的基础上发现新的/缺失的信息。除此之外,PSL还概率性地计算置信值,该置信值是[0,1]范围内(包括[0,1])的软真值,以表明PSL程序根据所提供的内容在多大程度上相信该事实是真实的。
一旦发现了新的/缺失的信息,并计算了它们的置信度,我们就可以构建一个具有高度置信事实的知识图谱。这将为我们提供一个图表,其中除了提取的原始事实之外,还可以获得无法明确驱动的新信息。这就是我们如何用知识库中的事实和基于现有观察结果的新发现的事实构建知识图谱。
最后,当我们总结知识图谱管道的这些级联步骤时,在更高的层次上,以下是构建知识图谱的过程。
阶段1:从自由文本中提取事实
数据是从自由文本、非结构化数据源和半结构化数据源中提取的。
对这些原始数据进行处理以提取信息。这涉及到实体、关系和属性的提取,这些属性是进一步定义实体和关系的属性。
如果数据已经结构化,则与步骤1不同,该数据将直接与来自第三方知识库的信息融合。
在此之后,将在融合的知识和处理后的数据之上应用各种自然语言处理技术。这包括共同引用解析、命名实体解析、实体消歧等等。
阶段2:根据提取的事实制定三元组
以上步骤结束了知识库信息的预处理。然后,进行本体提取过程,对提取的实体及其各自本体下的关系进行分类。
在进行本体形式化的过程中,事实将被提炼并作为三元组存储在知识库中。
阶段3:构建具有新链接和置信度的知识图谱
为了从知识库中构造知识图谱,将在这些三元组上应用统计关系学习(SRL)。
SRL过程计算每个事实(而不是整个领域)的置信度,以确定这些事实的真实程度。
在构建知识图谱时,将使用置信度来识别缺失的链接,并形成新推断的关系链接。
由于推理中的置信度包含在知识图谱中,一旦构建了图,就可以基于置信度来决定事实在多大程度上被认为是真实的。因此,Cayley生成的电影演员领域的示例知识图谱如下所示。
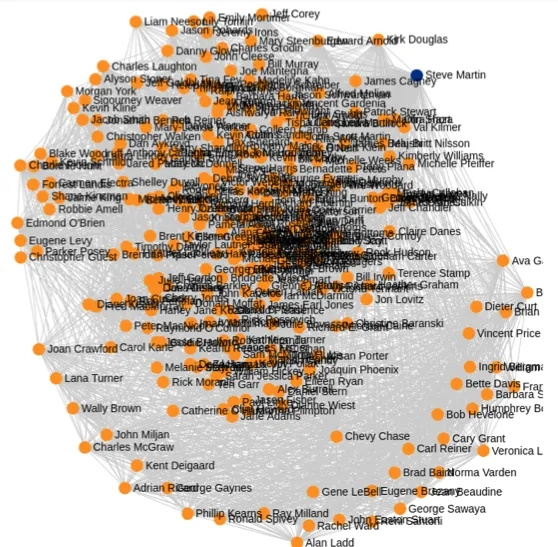
随后,这种知识图谱可以用于信息检索系统、聊天机器人、网络应用程序、知识管理系统等,以有效地提供对用户查询的响应。
结论
到目前为止,我们已经提供了整个知识图谱管道如何工作的抽象解释。使用这些阶段中指定的技术将保证发现丢失的链接。尽管如此,在知识图谱中仍然存在大量需要深度探索的内容,中培IT学院机器学习、深度学习、计算机图像处理及知识图谱应用与核心技术实战课程内容包括如何从0到1完成知识图谱构建,从实战的角度对深度学习技术进行了全面的剖析,并结合实际案例分析和探讨深度学习的应用场景,给深度学习相关从业人员以指导和启迪,推荐大家学习。
 400-808-2006
400-808-2006






 扫码加老师微信
扫码加老师微信
 微信服务号
微信服务号