
机器学习:算法原理、应用与示例
机器学习是一门涉及广泛且不断发展的领域,其包含多种算法,能够解决不同类型的问题,如分类、回归、聚类、降维等。在本文中,我将详细介绍几种常用的机器学习算法,包括它们的基本原理、应用场景以及一些Python代码示例。更多知识您可以参考人工智能实践项目案例分析与实战应用课程。
1. 线性回归(Linear Regression)
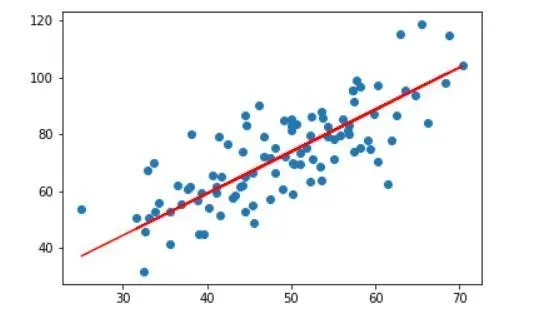
线性回归是一种经典的回归算法,用于建模两个或多个变量之间的线性关系。它被广泛应用于预测分析和趋势预测等任务中。
原理:
线性回归的核心思想是寻找一条最佳拟合直线(或超平面),以描述自变量(X)和因变量(Y)之间的关系。其基本公式可以表示为:
[ Y = \beta_0 + \beta_1X_1 + \cdots + \beta_nX_n + \epsilon ]
其中,( \beta ) 是系数,( \epsilon ) 是误差项。
应用场景:
线性回归适用于许多实际场景,包括但不限于:
预测房价:通过考虑各种房屋特征(如面积、地理位置等),可以使用线性回归模型来预测房价。
股票价格预测:线性回归可用于分析股票价格与各种因素(如市场指数、公司财务指标等)之间的关系,从而进行价格预测。
评估因素影响:线性回归可以用来评估各种因素对结果的影响大小和方向,例如产品销量与广告投入之间的关系。
Python代码示例:
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
import numpy as np
# 生成模拟数据
X = np.random.rand(100, 1)
y = 2 * X + 1 + np.random.randn(100, 1) * 0.05
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# 创建线性回归模型并训练
model = LinearRegression()
model.fit(X_train, y_train)
# 预测和评估
predictions = model.predict(X_test)
2.决策树(Decision Tree)
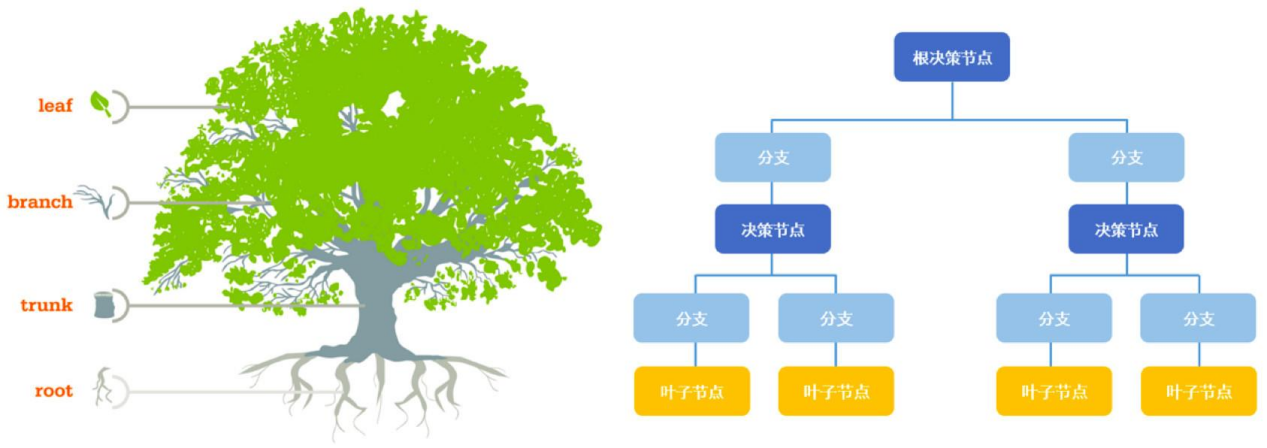
决策树是一种树形结构模型,用于数据分类和回归。它通过一系列规则对数据进行分割,以实现分类或回归的目标。
原理:
从根节点开始,根据特征的某个值将数据集分割成不同的分支。这个过程在每个分支上递归进行,直到满足停止条件,比如分支下的所有数据属于同一类别,或达到预定的深度限制。
应用场景:
客户细分
信用评分
医疗诊断
这些场景中,决策树可以帮助确定客户群体特征、预测信用风险或诊断疾病,通过简单的规则树结构提供可解释性强的结果。
Python代码示例:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
# 加载数据
iris = load_iris()
X, y = iris.data, iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# 创建决策树模型并训练
model = DecisionTreeClassifier()
model.fit(X_train, y_train)
# 预测和评估
predictions = model.predict(X_test)
3.支持向量机(Support Vector Machine, SVM)
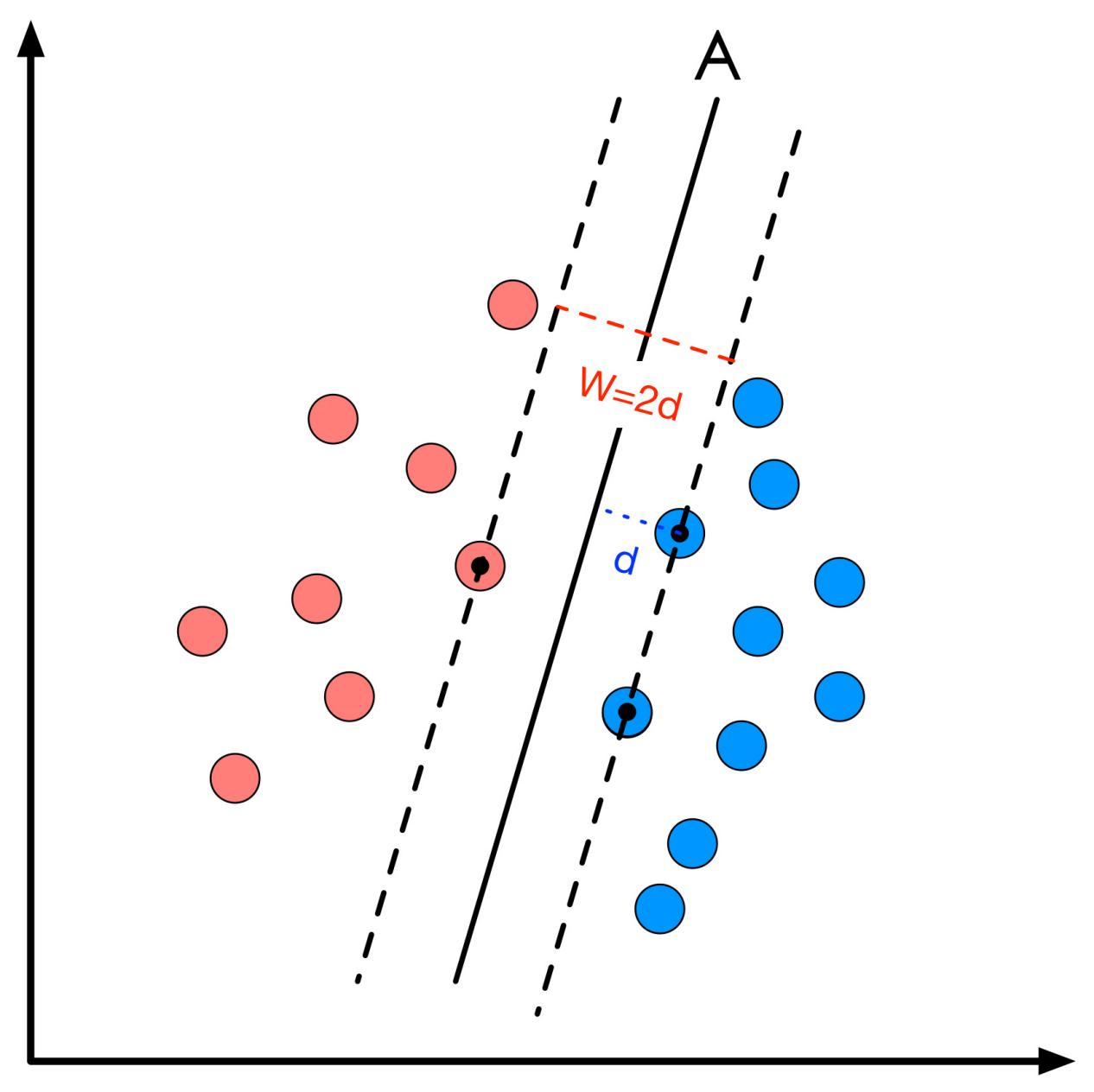
支持向量机是一种二分类模型,其核心思想是在特征空间中找到一个最大间隔的线性分类器,以区分不同类别的数据点。
原理:
支持向量机的核心概念在于寻找一个最优的分隔超平面,该超平面能够将不同类别的数据点分开,并且使得距离超平面最近的数据点(称为支持向量)到超平面的距离最大化。
应用场景:
支持向量机在多个领域有广泛的应用,包括但不限于:
文本分类
图像识别
生物信息学领域的分类问题
支持向量机以其强大的分类能力成为处理复杂数据集和解决非线性问题的有效工具之一。
Python代码示例:
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_classification
# 生成模拟数据
X, y = make_classification(n_samples=100, n_features=20, n_classes=2)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# 创建SVM模型并训练
model = SVC(kernel='linear') # 线性核
model.fit(X_train, y_train)
# 预测和评估
predictions = model.predict(X_test)
这些只是机器学习领域中众多算法中的一小部分。每种算法都拥有独特的优势和适用场景。在实际应用中,选择合适的算法往往取决于问题的性质、数据的类型和规模,以及期望的输出类型等多种因素。通过持续的实践和学习,你将能够更深入地理解这些算法,并有效地将它们应用于解决实际问题。
想获得持续深入的人工智能领域知识?您可以了解中培IT学院>人工智能实践项目案例分析与实战应用课程,本课程从实战的角度对深度学习技术进行了全面的剖析,并结合实际案例分析和探讨深度学习的应用场景,给深度学习相关从业人员以指导和启迪。
报名热线:400-808-2006 / 13910781835 (同微)
 400-808-2006
400-808-2006






 扫码加老师微信
扫码加老师微信
 微信服务号
微信服务号