培训背景
「CDA 数据分析师人才行业标准」是面向全行业数据分析及大数据相关岗位的一套科学化、专业化、正规化、系统化的人才技能准则。CDA数据分析师认证考试是评判「标准化人才」的唯一考核路径。CDA考试大纲规定并明确了数据分析师认证考试的具体范围、内容和知识点,考生可按照大纲要求进行相关知识的学习,获取技能,成为专业人 才。
认证价值
部分政企项目招标要求的加分资格认证
自2013年以来,众多企业在部分政企项目竞标过程中,被要求提供CDA认证证书,作为企业数据业务能力重要资质,且需要团队有一定人数以上的CDA持证人才符合招标要求,可在评标过程中获得加分优势。
部分企业晋升员工加薪的重要依据
根据《2020年CDA持证人报告》,持证人普遍薪资高于非持证人,在企业中获得晋升,也是企业内部职位提升与加薪条件之一。
更多的官方认可打通证书价值链
考核通过后,获得的CDA数据分析师中文证书,由中国成人教育协会数据分析教育培训专业委员会监制。
部分企业招聘持证人优先
联通、神州数码、中软国际等企业招聘职位描述中将CDA持证人列入优先考虑。
德勤(Deloitte)将CDA认证纳入员工手册,给予员工CDA考试补贴。
中国电信、苏宁等企业引进CDA人才参考标准,在企业内部推动CDA认证考试。
适合人群
零基础就业转行人群
高校应往届毕业生人群
研发、技术岗在职人群
产品、运营、营销等业务人群
待业、期待转行从事数据分析工作人员
可借助数据分析提高工作效率的人群
对数据分析感兴的高校教师
对商业BI数据分析感兴趣的各界人士
企业创始人、经理人、管理咨询类岗位从业人群
考试须知
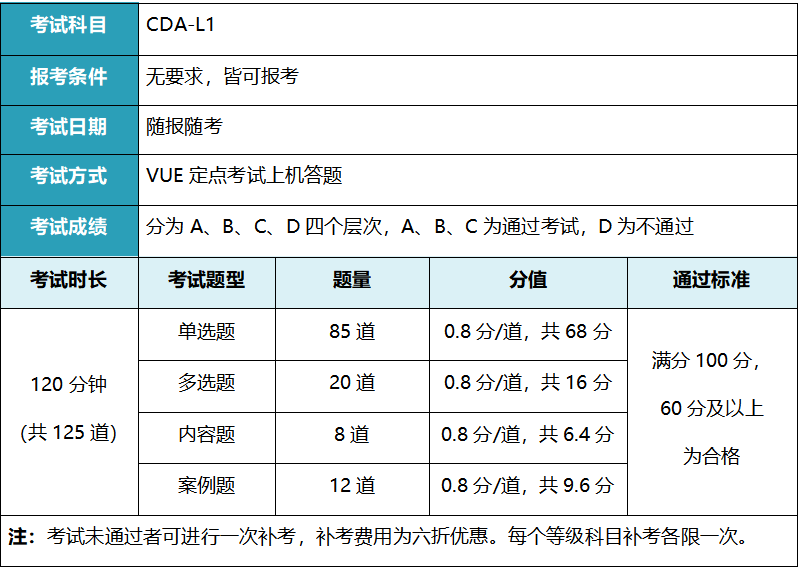
课程大纲
|
日程
|
章节
|
核心内容
|
|
第一天
上午
|
第 1 章
数据分析思维
|
1.VUCA 时代的数据分析需求:
Ø 数据分析的归纳与演绎方法。
2.流程化企业数据分析需求:
Ø 介绍流程化企业特点
Ø 数据分析在流程中的落脚点
3.企业数字化转型的进展:
Ø 以用户体验为中心的商业模式
Ø 以数据分析为中心的架构模式转型
Ø 感知型企业的发展目标
4.企业需要的数据应用能力:
Ø 概述企业数据应用能力
Ø 分析不同决策层级(战略层、管理层、运营层、操作层)对数据的需求
5.数据分析的基本概念:
Ø 讲解对数据和数据模型的理解
Ø 数据分析的分类
Ø 商业数据科学应用框架 EDIT
6.知识小结与 QA 问答
|
|
第 2 章
数据分析方法(上)
|
1.数据分析的基础范式:
Ø 分类分析
Ø 链式分析
Ø 相关分析
2.由基础分析范式引申出的 6 种分析方法:
Ø 趋势分析法
Ø 对比分析法
Ø 构成分析法
Ø 分布分析法
Ø 关系分析法
Ø 流向分析法
|
|
第一天
下午
|
第 2 章
数据分析方法(下)
|
1.统计制图原理:
Ø 整理数据
Ø 明确要表达的信息
Ø 确定比较的类型和图表类型
Ø 统计图的补充说明
2.知识小结与 QA 问答
|
|
第 3 章
商业数据分析框架
|
1.商业数据分析体系构建:
Ø 从战略、财务、客户关系、内部流程、员工成长与文化建设视角展开
2.商业数据分析总体流程:
Ø 分别介绍业务角度和技术角度的流程
3.各视角分析方法及示例:
Ø 远景战略分析(企业 SWOT 分析示例)
Ø 财务视角分析(企业收入趋势、财务费用趋势分析示例)
Ø 客户与市场视角分析(用户细分分析、电商平台客户个性化营销示例)
Ø 内部流程视角分析(VSM 价值流分析、银行贷款流程优化示例)
4. 知识小结与 QA 问答
|
|
第二天
上午
|
第 4 章
战略数据分析
|
1.战略数据分析基础:
Ø 表格结构数据操作说明
Ø 输入数据和资源需求
2. 战略数据分析关键步骤:
Ø 桌面研究(概述、行业分析方法和流程、竞品分析方法和流程)
Ø 调查研究(流程、定性方法和定量方法)
3. 战略数据分析报告呈现
4. 知识小结与 QA 问答
|
|
第 5 章
业务数据分析(上)
|
1. 业务数据分析基础:
Ø 业务数据分析产出物
Ø 关键术语
2. 输入和资源需求:
Ø 输入需求
Ø 资源需求
|
|
第二天
下午
|
第 5 章
业务数据分析(下)
|
1. 业务数据分析的步骤:
Ø 明确业务关注事项
Ø 发现问题
Ø 归因分析
Ø 优化策略
Ø 验证想法
2. 报告呈现
3. 知识小结与QA问答
|
|
第 6 章
描述性统计分析
|
1. 变量度量类型与统计量:
Ø 变量度量类型与分布类型
Ø 分类变量、连续变量(集中趋势、离散程度)的参数
Ø 数据分布的对称与高矮
Ø 统计量与报表和统计制图的关系
2. 总体参数和样本统计量
3. 参数估计方法:点估计、区间估计和中心极限定理
4. 知识小结与QA问答
|
|
第三天
上午
|
第 8 章
SQL 语言基础与 MySQL 入门
|
1. SQL 语言概况
2. SQL 查询语句:
Ø 简单查询并对数据过滤与排序
Ø 创建新列
Ø 在查询中实现汇总和分组汇总
Ø 表的横向连接、子查询、表纵向合并
Ø 集合操作语句
3. SQL 创建表或视图
4. 知识小结与 QA 问答
|
|
第三天
下午
|
第 7 章
指标体系构建方法
|
1. 指标概述:
Ø 指标的基本概念
Ø 指标值的计算
2. 通用指标介绍:
Ø 求和类、计数类、比较类指标计算方法
3. 场景指标介绍:
Ø 按企业产品类型、部门职能划分
4. 指标体系介绍:
Ø 从技术加工、业务层级角度分类,介绍指标库、维度库
5. 指标体系自上而下搭建方法:
Ø 设计框架
Ø 核心术语和主要技术
Ø 设计方法
Ø 实践方案
6. 知识小结与 QA 问答
|
|
第 9 章
用户标签体系与用户画像专题
|
1. 案例:
Ø 某企业基于用户标签的营销
2. 标签的分类:
Ø 从研究客体的数据类型、标签的时态、标签的加工角度分类
3. 用户画像:
Ø 用户分群的发展历程
Ø 快速入手用户画像
Ø 用户细分的方法
4. 案例:
Ø 用 SQL 和 Excel 实现用户画像(思路、数据集介绍、SQL 数据处理、Excel 做用户画像)
5. 知识小结与 QA 问答
|
|
第四天
上午
|
第 10 章
简单时间序列分析方法
|
1. 认识时间序列
2. 效应分解法时间序列分析:
Ø 直观理解
Ø 算法解析
Ø 使用 Power BI 演示
3. 案例:时间序列预测
4. 知识小结与 QA 问答
|
|
第 11 章
数据治理
|
1. 数据治理驱动因素
2. 数据治理体系:
Ø 数据治理域
Ø 数据管理域
Ø 数据应用域
3. 如何开展数据治理:
Ø 准确地定位数据治理
Ø 明确数据应用方向
Ø 多层级全方位进行治理
4. 知识小结与 QA 问答
|
|
第四天
下午
|
第 12 章
数据模型与数据建模
|
1. 数据分类
2. 数据架构和数据模型:
Ø 数据架构的基本概念
Ø 数据模型基础和数据模型类型
Ø 数据建模的层次
3. 数据仓库体系和 ETL
4. ETL 与 ELT 区别
5. 数仓与数湖结构分析
6. 知识小结与 QA 问答
|
|
第 13 章
指标体系管理
|
1. 指标管理:
Ø 指标数据元和指标数据标准
Ø 指标数据质量评价维度
2. 企业级指标体系建设方法与步骤:
Ø 指标体系构建方法
Ø 全生命周期建设步骤
3. 指标体系管理的问题与挑战:
Ø 常见问题
Ø 面临的挑战
4. 指标体系管理:
Ø 指标体系的生命周期
Ø 管理体系
5. 知识小结与 QA 问答
|
授课专家
郭老师 数据分析专家 | 中培IT学院特聘金牌讲师
郭老师长期致力于数据管理、大数据分析及信息化架构领域的研究与实践。作为DAMA大中华区特聘培训讲师、工信部大数据工程技术人员教材撰写专家,他不仅在数据治理体系构建、数据资产管理等方面具备深厚理论功底,更在业务数据分析的实际应用与人才培养方面积累了丰富经验。
郭老师曾多次为中央企业、金融机构及政府部门提供数据类项目咨询与规划服务,并主导多类大数据分析与可视化项目实战。其授课风格深入浅出,逻辑清晰,善于将复杂的数据分析理论转化为易于理解和应用的实操内容。课程不仅注重认证考试要点,更强调实际工作中的问题解决与价值落地,深受学员与企业好评。
培训费用
培训费:3980元/人
考试费:1200元/人(含考试费发票)。
 400-808-2006
400-808-2006



 扫码加老师微信
扫码加老师微信
 微信服务号
微信服务号