 400-808-2006
400-808-2006

AI大模型全栈工程师实战训练营培训班

一、培训特色
1. 理论与实践相结合、案例分析与实验穿插进行;
2. 专家精彩内容解析、学员专题讨论、分组研究;
3. 通过全面知识理解、专题技能掌握和安全实践增强的授课方式。
二、培训对象
Ø 从事人工智能领域工作的人
如果你正在从事人工智能、机器学习、数据分析等相关领域的工作,或者想要进入这些
领域,那么学习AI大模型开发将会对你的职业发展有很大的帮助。
Ø 软件工程师和架构师
这类专业人士可以通过学习AI大模型开发课程来提升团队的研发效率,了解大模型如何影响软件架构,并掌握基于大模型的全新开发范式。
Ø 对人工智能有浓厚兴趣的人
对人工智能、机器学习等领域有浓厚的兴趣,想要深入了解并掌握相关技能,并有一定的软件开发基础的从业者。
三、培训收益
Ø 1.整体掌握大模型理论知识;
Ø 2.了解自注意力机制、Transformer模型、BERT模型;
Ø 3.掌握DeepSeek与ChatGPT原理与实战;
Ø 4.了解LLM应用程序技术栈和提示词工程Prompt Enginerring;
Ø 5.了解国产大模型ChatGLM;
Ø 6.了解视觉大模型技术优势;
Ø 7.掌握语言理解与字幕生成及其应用;
Ø 8.掌握图像生成和应用实操;
Ø 9.了解应用场景与潜力分析;
Ø 10.了解大模型企业商用项目实战。
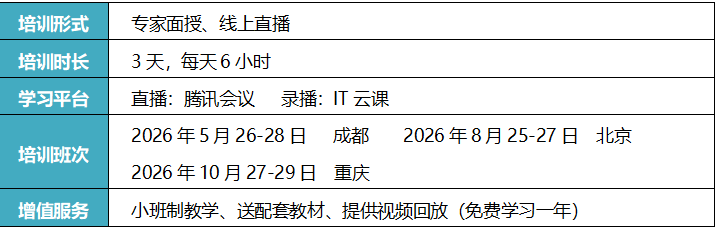
四、日程安排
|
培训时间 |
培训主题 |
培训大纲 |
|
第一天
|
预备知识第一节:大模型理论知识 |
1. 初探大模型:起源与发展 2. GPT模型家族:从始至今 3. 大模型DeepSeek VS ChatGPT4的对比介绍 4. 大模型实战-大模型2种学习路线的讲解 5. 大模型最核心的三项技术:模型、微调和开发框架 6. DeepSeek的MoE 混合专家模型介绍 7. DeepSeek-R3后训练阶段与强化学习技术介绍 8. OpenAl文本模型A、B、C、D四大模型引擎简介 9. 最强Embedding大模型text-embedding-ada模型介绍 10. 全球开源大模型性能评估榜单 11. 中文大模型生态介绍与GLM 130B模型介绍 12. DeepSeek模型介绍与部署门槛 13. DeepSeek开源生态:微调、多模态,WebUI等项目简介 |
|
预备知识第二节:自注意力机制、Transformer模型、BERT模型 |
1. RNN-LSTM-GRU等基本概念 2. 编码器、解码器 3. 自注意力机制详解 4. Transformer 5. Mask Multi-Head Attention 6. 位置编码 7. 特定于任务的输入转换 8. 无监督预训练、有监督 Fine-tuning 9. BERT思路的理解 10. BERT模型下游任务的网络层设计 11. BERT的训练 12. HuggingFace中BERT模型的推断 13. 基于上下文的学习 14. 代码和案例实践: 基本问答系统的代码实现 深入阅读理解的代码实现 段落相关性代码实现 |
|
|
第三节: Embedding模型实战 |
1. 大模型技术浪潮下的Embedding技术定位 2. Embedding技术入门介绍 3. 从Ono-hot到Embedding 4. Embedding文本衡量与相似度计算 5. OpenAl Embedding模型与开源Embedding框架 6. 两代OpenAl Embedding模型介绍 7. text-embedding-ada-002模型调用方法详解 8. text-embedding-ada-002模型参数详解与优化策略 9. 借助Embedding进行特征编码 10. Embedding结果的可视化展示与结果分析 【实战】借助Embedding特征编码完成有监督预测 【实战】借助Embedding进行推荐系统冷启动 【实战】借助Embedding进行零样本分类与文本搜索 11. Embedding模型结构微调优化 12. 借助CNN进行Embedding结果优化 【企业级实战】海量文本的Embedding高效匹配 |
|
|
第四节: LLM应用程序技术栈和提示词工程Prompt Enginerring |
1. 设计模式:上下文学习 2. 数据预处理/嵌入 3. 提示构建/检索 4. 提示执行/推理 5. 数据预处理/嵌入 6. Weaviate、Vespa 和 Qdrant等开源系统 7. Chroma 和 Faiss 等本地向量管理库 8. pgvector 等OLTP 扩展 9. 提示构建/检索 10. 提示执行/推理 11. 新兴的大语言(LLM)技术栈 12. 数据预处理管道(data preprocessing pipeline) 13. 嵌入终端(embeddings endpoint )+向量存储(vector store) 14. LLM 终端(LLM endpoints) 15. LLM 编程框架(LLM programming framework) 16. LangChain的主要功能及模块 17. Prompts: 这包括提示管理、提示优化和提示序列化。 18. LLMs: 这包括所有LLMs的通用接口,以及常用的LLMs工具。 19. Document Loaders: 这包括加载文档的标准接口,以及与各种文本数据源的集成。 20. Utils: 语言模型在与其他知识或计算源的交互 21. Python REPLs、嵌入、搜索引擎等 22. LangChain提供的常用工具 23. Indexes:语言模型结合自定义文本数据 24. Agents:动作执行、观测结果, 25. LangChain的代理标准接口、可供选择的代理、端到端代理示例 26. Chat:Chat模型处理消息 27. 代码和案例实践: LLM大模型的使用 Prompts的设计和使用 |
|
|
第二天 |
第五节: 国产大模型DeepSeek |
1. 新一代DeepSeek模型API调用 2. DeepSeek开放平台使用方法与APIKey申请 3. DeepSeek-V3、DeepSeek-R1、DeepEP介绍 4. DeepSeek在线知识库使用及模型计费说明 5. DeepSeek模型SDK调用与三种运行方法 6. DeepSeek调用函数全参数详解 7. DeepSeek Message消息格式与身份设置方法 8. DeepSeek tools外部工具调用方法 9. DeepSeek Function calling函数封装12GLM4接入在线知识库retrieval流程 10. DeepSeek接入互联网web_search方法 【实战】基于DeepSeek打造自动数据分析Agent 【实战】基于DeepSeek的自然语言编程实战 【实战】基于DeepSeek Function call的用户意图识别 【实战】基于GLM4的长文本读取与优化 |
|
第六节:LangChain大模型框架构建 |
1. 构建垂直领域大模型的通用思路和方法 (1) 大模型+知识库 (2) PEFT(参数高效的微调) (3) 全量微调 (4) 从预训练开始定制 2. LangChain介绍 3. LangChain模块学习-LLMs 和 Prompts 4. LangChain之Chains模块 5. LangChain之Agents模块 6. LangChain之Callback模块 7. Embedding嵌入 8. 自定义知识库 9. 知识冲突的处理方式 10. 向量化计算可采用的方式 11. 文档加载器模块 12. 向量数据库问答的设计 13. Lanchain竞品调研和分析 14. Dust.tt/Semantic-kernel/Fixie.ai/Cognosis/GPT-Index 15. LlamaIndex介绍 16. LlamaIndex索引 17. 动手实现知识问答系统 18. 代码和案例实践: 动手实现知识问答机器人 LangChain文本摘要 PDF文本阅读问答 |
|
|
第七节 使用LangGraph构建工作流 |
1. LangGraph 构建自适应RAG 2. LangGraph 应用场景、核心功能、特点 3. 基础概念:节点、边、图等 4. LangGraph 的系统架构 5. 数据模型和存储机制 6. 基本数据查询与操作 7. 高级查询:路径查询、模式匹配 8. 使用本地LLM自适应RAG 9. 代理RAG与纠正(CRAG) |
|
|
第三天 |
第八节 LLM模型的私有化部署与调用
|
1. LLM 推理与本地私有化部署 2. 各种模型文件介绍 3. 模型的推理、量化介绍与实现 4. Modelscope、Hugging Face简单介绍与使用 5. 大模型管理底座Ollama介绍 6. Ollama + lLama 部署开源大模型 7. Open WebUI发布与调用大模型 8. API Key获取与 Llama微调实现 |
|
第九节 开源大模型微调实现 |
1. Llama_Factory 微调实战 2. 提升模型性能方式介绍:Prompt、知识库、微调 3. 如何科学构建训练数据(基础与专业数据混合训练) 4. 微调常见方式介绍:微调、偏好对齐、蒸馏、奖励模型 5. Llama3 模型架构与调用申请 6. 数据上传与任务创建(job) 7. 训练集与测试集拆分与模型评估 8. Unsloth微调平台介绍 9. Llama3开源大模型的微调与使用 10. 模型的评估策略 |
|
|
第十节 大模型企业商用项目实战 |
1. AI-Agent 构建可发布的智能客服系统 2. 智能体介绍与AutoGPT基本原理 3. AutoGPT安装与环境配置 4. 实战体验:AutoGPT实现数据爬取、清洗、保存 5. 创建各种场景的AutoGPT 6. 内容创建 7. 客服服务 8. 数据分析 9. 代码编写 10. 创建应用程序 |
五、授课专家
刘老师 | 国内顶尖AI专家
拥有十几年软件研发经验,十年企业培训经验,对Java、Python、区块链等技术领域有独特的研究,精通J2EE企业级开发技术。Java方向:设计模式、Spring MVC、MyBatis、Spring、StringBoot、WebService、CXF并且对Java源码有深入研究。Python方向:Python OOP、Mongodb、Django、Scrapy爬虫、基于Surprise库数据推荐,Tensorflow人工智能框架、人脸识别技术。区块链方向:BitCoin、Solidity、Truffle、Web3、IPFS、Hyperledger Fabirc、Go、EOS。
邹老师 | 长春工业大学人工智能研究院院长
工程学术带头人、华东建筑设计研究总院研究员、山东交通学院客座教授、南昌航空大学硕士生导师、中国软件行业协会专家委员、上海市计划生育科学研究所特聘专家、天津大学创业导师、中华中医药学会会员、中国医药教育协会老年运动与健康分会学术委员;领导睿客邦与全国二十多所高校、国企建立了AI联合实验室,完成50多个深度学习实践项目,广泛应用于医疗、交通、农业、气象、银行、电信等多个领域。
带队完成了数十个AI项目,内容不仅包括深度学习、机器学习、数据挖掘等具体技术要点,也包括AI的整体发展、现状、应用、商业价值、未来方向等,涵盖内容非常丰富。
六、培训费用
培训费:6800元/人(含培训费、平台费、资料费及直播视频回放一年等费用)。
相关阅读

-
【全国统一报名热线:400-808-2006】
蒋老师:13260025235 (微信同号) QQ: 2210585665
倪老师:18701378400 (微信同号) QQ:1658122838
方老师:13910781835 (微信同号) QQ:1808273142 -
 扫码加老师微信
扫码加老师微信
-
 微信服务号
微信服务号
中培IT学院 Copyright © 2006-2025 北京中培伟业管理咨询有限公司 .All Rights Reserved
京ICP备13024721号-3 地址:北京市丰台区育芳园东里3号楼B座 邮编:100071